Demo
Abstract
We present LoRA-SP (Select–Prune), a rank-adaptive fine-tuning method that replaces fixed-rank updates with input- and layer-wise capacity. LoRA-SP uses an SVD-style parameterization with a small router whose nonnegative scores act as singular values over a shared vector bank. The active set is chosen by an energy target on the cumulative squared scores E(k) ≥ η, providing a direct link to approximation error. During training, η concentrates energy on a few directions while preserving accuracy, yielding compact adapters that reduce cross-task interference and improve generalization.
On four real-robot manipulation tasks with an unseen AgileX PiPER arm, across π₀ and SmolVLA backbones, LoRA-SP matches or exceeds full fine-tuning and improves multi-task success by up to +31.6% over standard LoRA while remaining robust to rank choice.
Method
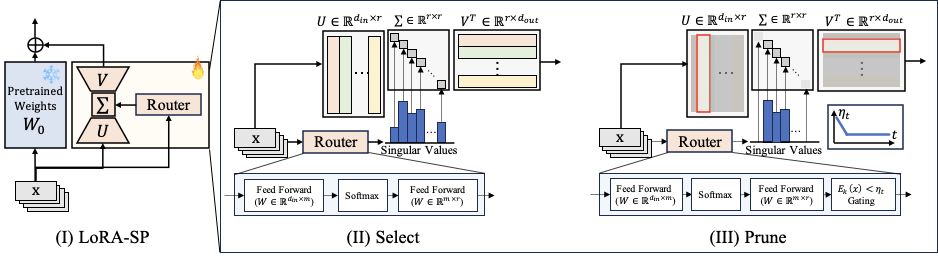
LoRA-SP generalizes standard LoRA by replacing the fixed-rank update ΔW = BA with:
where Uℓ, Vℓ define a shared vector bank (initialized wide at r = 128), and sℓ(x) ≥ 0 are singular-value-like scores produced by a lightweight router per input.
Select: Energy-based Active Rank
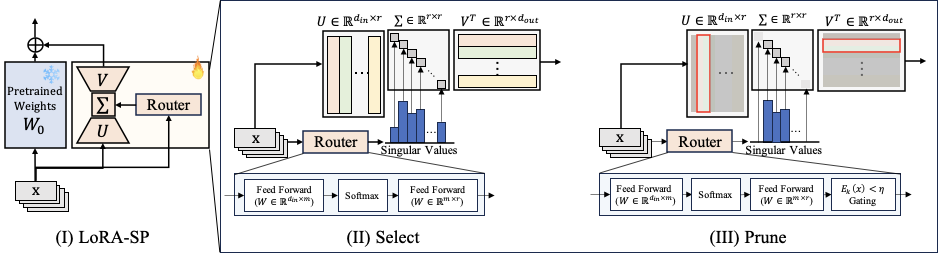
Router scores are sorted and the effective rank k is the smallest index satisfying:
Since Ek(x) bounds the relative Frobenius error as √(1 − Ek(x)), the threshold η is a direct accuracy–efficiency knob. Vectors beyond rank k are zeroed for that input.
Prune: Spectral Concentration Loss
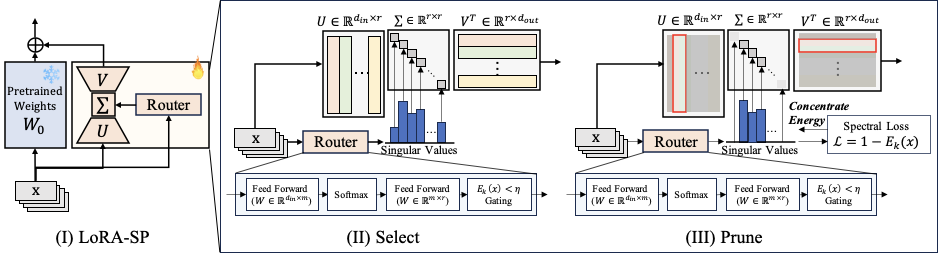
This creates a positive feedback loop: selected vectors are reinforced, their singular values grow, and they dominate future selections. The task loss prevents accuracy collapse, yielding compact adapters without sacrificing performance.
Layer-wise Rank Distribution
Experiments

Setup
- Robot: AgileX PiPER (7-DoF), unseen during VLA pretraining
- Tasks: Open the Pot · Pour the Block · Press the Button · Pick and Place
- Data: 120 demos per task (480 total), dual RGB views
- Backbones: π₀ (PaLIGemma-3.5B) and SmolVLA (SmolVLM-2-based)
- Baselines: Full FT, LoRA (r ∈ {16,32,64,128}), AdaLoRA, LoRA-MoE
Main Results
| Method | π₀ Multi-Task Avg | SmolVLA Multi-Task Avg |
|---|---|---|
| Full Fine-Tuning | Best | Best |
| LoRA (r=128) | Baseline | Baseline |
| AdaLoRA | ≈ LoRA | ≈ LoRA |
| LoRA-MoE (weighted) | ≈ LoRA | ≈ LoRA |
| LoRA-SP (ours) | +23.3% over LoRA | +31.6% over LoRA |
LoRA-SP matches or exceeds full fine-tuning across tasks while updating significantly fewer parameters and remaining robust to rank choice.
Rank vs. Performance
Citation
@inproceedings{kim2026lorasp,
author = {Donghoon Kim and Minji Bae and Unghui Nam and
Gyeonghun Kim and Suyun Lee and Kyuhong Shim and Byonghyo Shim},
title = {Adaptive Capacity Allocation for Vision Language Action Fine-tuning},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2026},
url = {https://arxiv.org/abs/2603.07404},
}